
Кластеризация — это процесс группировки набора объектов таким образом, чтобы сходство между объектами внутри одного кластера было максимальным.
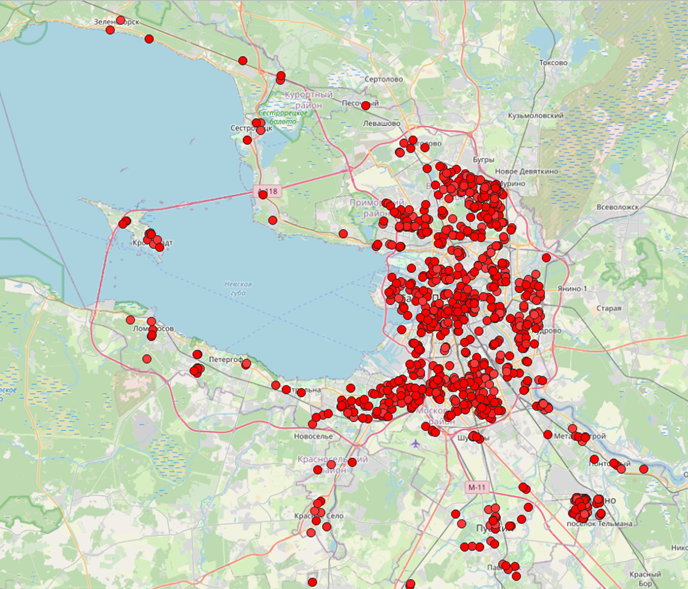
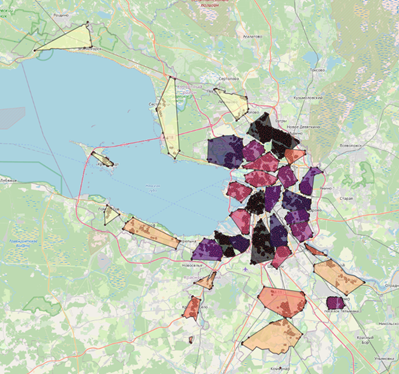
Карта с точками до и после кластеризации в Санкт-Петербурге. До кластеризации (1), После кластеризации (2).
При работе с пространственными данными их часто полезно превратить в кластеры. Например, чтобы:
- выявить «горячие точки» — места наибольшей плотности заболеваний, преступности, ДТП;
- объединить районы со схожими социальными условиями;
- выявить места с одним типом землепользования.
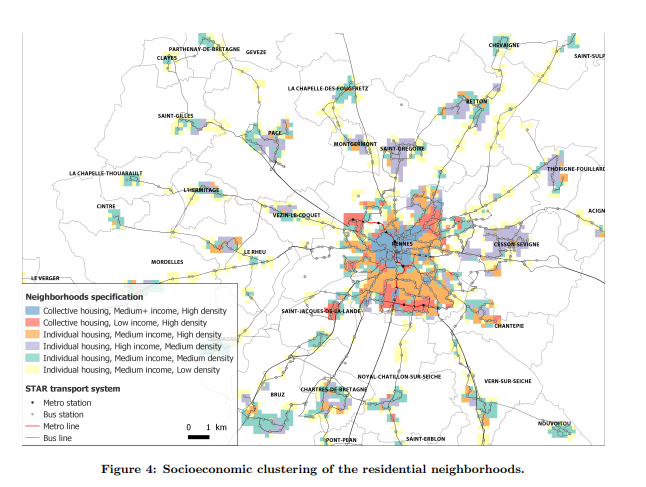
Пример кластеризии пространственных данных: в кластеры объединились кварталы, схожие по социально-экономическим условиям. Картинка из статьи El Mahrsi et al., 2014..
При кластеризации пространственных данных важно учитывать взаимное расположение объектов и помнить основные особенности.
Пять особенностей кластеризации пространственных данных
Возможность обнаружения кластеров неправильной формы
Необходимо, чтобы алгоритмы могли учитывать неправильные формы. Самый популярный алгоритм кластеризации, K-means, лучше всего справляется с обнаружением скоплений сферической формы. Алгоритмы кластеризации на основе плотности, например, DBSCAN, больше подходят для поиска кластеров произвольной формы, которая чаще встречается у геоданных.
Количество кластеров определяется расположением данных
Грамотный анализ пространственных данных не должен предполагать наличие четкого количество кластеров. В некоторых случаях данные могут содержать несколько кластеров, которые пересекаются или находятся вблизи друг друга, поэтому лучше использовать алгоритм, который обнаружит естественные границы между кластерами.
Учет выбросов
Пространственные данные часто содержат выбросы — значения, которые сильно выделяются из общего набора данных. Точность анализа зависит от их учета, поэтому, алгоритмы, используемые для обработки, должны быть способны работать с нетипичными значениями. Например, алгоритмы, основанные на плотности, могут более эффективно обрабатывать шум, в отличие от алгоритмов на основе расстояния.
Параметры на входе алгоритма должны учитывать расстояние между объектами
Большая часть алгоритмов кластеризации чувствительна к гиперпараметрам, то есть параметрам,заданным пользователем. Даже плотностные алгоритмы, на вход которым не нужно задавать определенное число кластеров, нуждаются в тщательном выборе порога плотности.
Определение кластеров с различной плотностью
В одном датасете схожие данные могут иметь разную плотность, поэтому алгоритмы кластеризации должны обрабатывать пространственные данные с различной плотностью. Этого можно добиться путем долгого подбора гиперпараметров у классических плотностных алгоритмов или зная тонкости работы более продвинутых алгоритмов.
К задаче кластеризации пространственных данных нужно подходить, понимая уникальные особенности набора данных и зная общие принципы кластеризации геоданных.
Другие материалы по кластеризации пространственных данных
Материал подготовила Анна Пикулева
