Время прочтения: 5 минут
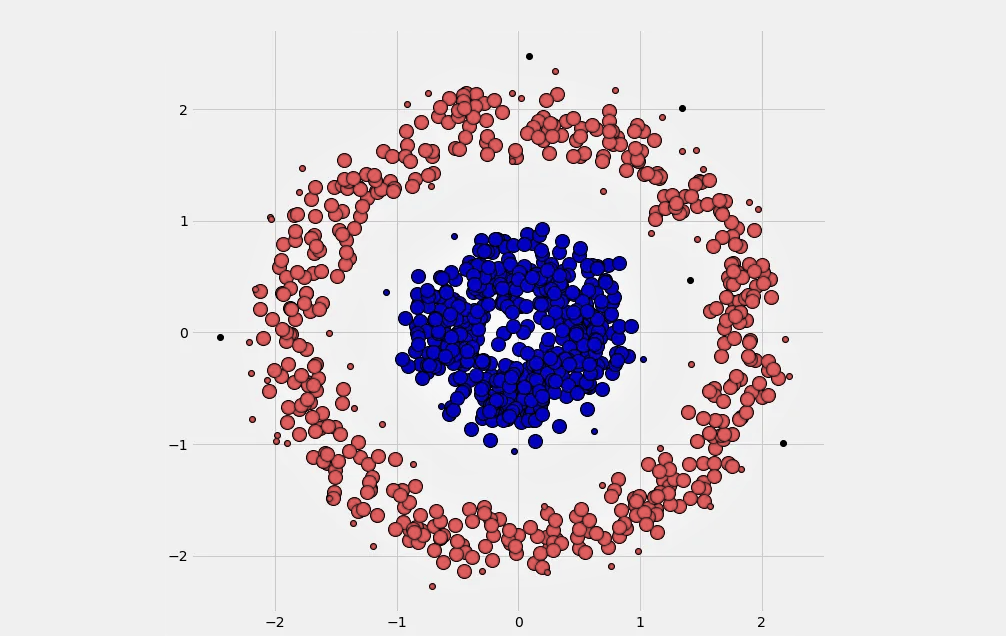
Алгоритмы кластеризации на основе плотности – это один из подходов при группировке пространственных данных. В прошлый раз мы поговорили про k-means и иерархические алгоритмы и протестировали их на наборе точечных данных. В сегодняшнем тексте покажем, как кластеризовать этот же набор с DBSCAN, и почему это лучше подойдет для наших данных.
Основное отличие плотностных алгоритмов от разделительных – возможность определять кластеры произвольной формы. Плотностные алгоритмы к тому же сами определяют необходимое количество кластеров.
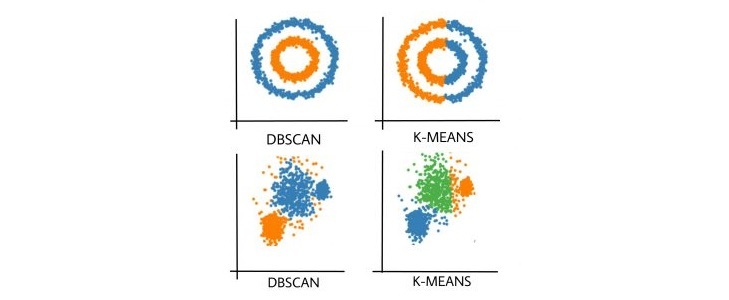
Сравнение DBSCAN и k-means. Источник: https://www.geeksforgeeks.org/dbscan-clustering-in-ml-density-based-clustering/
Основной принцип работы плотностных алгоритмов – это выделение областей высокой концентрации точек, которые разделяются областями с низкой плотностью. Точки, которые попали в области с низкой плотностью, определяются как выбросы.
Кластеризация на основе плотности – наиболее грамотный алгоритм для пространственных данных. Например, для того, чтобы выявить области с наибольшим количеством ДТП или определить области заболеваний, вероятнее всего прибегнут к плотностным алгоритмам.
Почему плотностные алгоритмы кластеризации подходят к геоданным
- Они умеют обнаруживать кластеры неправильной формы. Происшествия на дороге, как и заболевания, могут быть по-разному расположены на территории.
- Плотностные алгоритмы учитывают выбросы. Если одно-два ДТП произошли вдали от города или один случай болезни был намного дальше от остальных, эти объекты не будут относиться в кластеры.
Алгоритмы кластеризации на основе плотности выявляют группы, которые находятся близко друг к другу в пространстве признаков, и они необходимы при поиске скрытых паттернов в данных. Различные модификации плотностных алгоритмов используются для выявления аномалий в данных или при сегментации изображений.
Про алгоритм DBSCAN
DBSCAN – самый популярный плотностной алгоритм. Плотность в этом алгоритме определяется количеством точек, а также расстоянием, на котором эти точки находятся.
Для DBSCAN основными гиперпараметрами на входе являются радиус окрестности и минимальное количество точек, которое может быть в одном кластере.
- Радиус окрестности. Если расстояние между любыми двумя точками меньше или равно заданному радиусу, эти точки считаются соседними. Радиус окрестности необходимо задавать исходя из расстояния между точками.
- Минимальное количество соседей (точек) в радиусе. Чем больше набор данных, тем больше точек должно быть выбрано.
Давайте разберемся, как эти гиперпараметры используются в работе алгоритма, а потом на примере посмотрим, как их выбирать.
Как работает алгоритм DBSCAN
1/ Алгоритм берет точку и строит от нее буфер указанного радиуса. Если в буфер попадает количество точек больше, чем минимальное количество точек в радиусе, то эта точка становится корневой и от нее строится новый кластер. Так выбираются все корневые точки.

2/ Далее алгоритм находит точки, у которых в буфере меньше заданного количества соседей, но есть хотя бы одна корневая точка. Эти точки становятся пограничными.

3/ Остались точки, в буфере от которых меньше указанного числа соседей и нет корневых элементов. Эти точки будут считаться выбросами.

4/ Если два корневых элемента находятся рядом, то они объединяются в один кластер.
5/ Пограничные элементы будут отнесены к группе корневого элемента из своей окрестности.
5/ Пограничные элементы будут отнесены к группе корневого элемента из своей окрестности.

6/ Процесс завершается, когда ни к одному кластеру не может быть добавлено ни одного нового объекта.
На сайте Naftali Harris можно еще раз посмотреть, как работает алгоритм DBSCAN и как будут меняться кластеры в зависимости от подбора гиперапараметров.
Пример использования DBSCAN
Проведем кластеризацию уже известного нам набора данных, используя алгоритм кластеризации DBSCAN. Как мы говорили ранее, для работы алгоритма необходимо подобрать два гиперпараметра:
- размер окрестности – eps;
- минимальное количество соседей в кластере – minpt.
Подбор размера радиуса окрестности
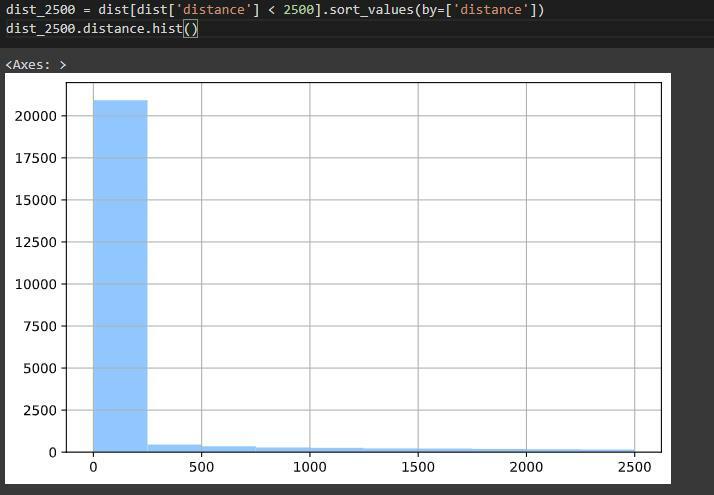
Для того, чтобы понять, какую окрестность выбрать, нам необходимо понять, как близко расположены точки в нашем наборе данных. Для этого сначала рассчитаем расстояние между ближайшими точками.

Мы получили, что большая часть точек имеет вблизи точку-соседа на расстоянии менее 250 метров. А так как необходимо, чтобы кластер образовывали несколько точек, возьмем диапазон расстояния окрестности от 500 до 1500 метров.
Подбор минимального количества точек в окрестности
Для минимального количества точек в окрестности будем перебирать итерационно значения от 10 до 100. Исходя из логических соображений, такие значения являются минимальными, учитывая, что датасет состоит из более 30000 объектов.
Гиперпараметры для нашего случая:
- Радиус (eps) – 500-1500 м;
- Минимальное количество точек (minpoints) – от 10 до 100.
Далее была написана функция, которая вычисляет оптимальные пары этих гиперпараметров, а после этого мы рассчитали кластеры. Всего на выходе получилось около 20 различных результатов работы алгоритма. Посмотрим на два удачных:
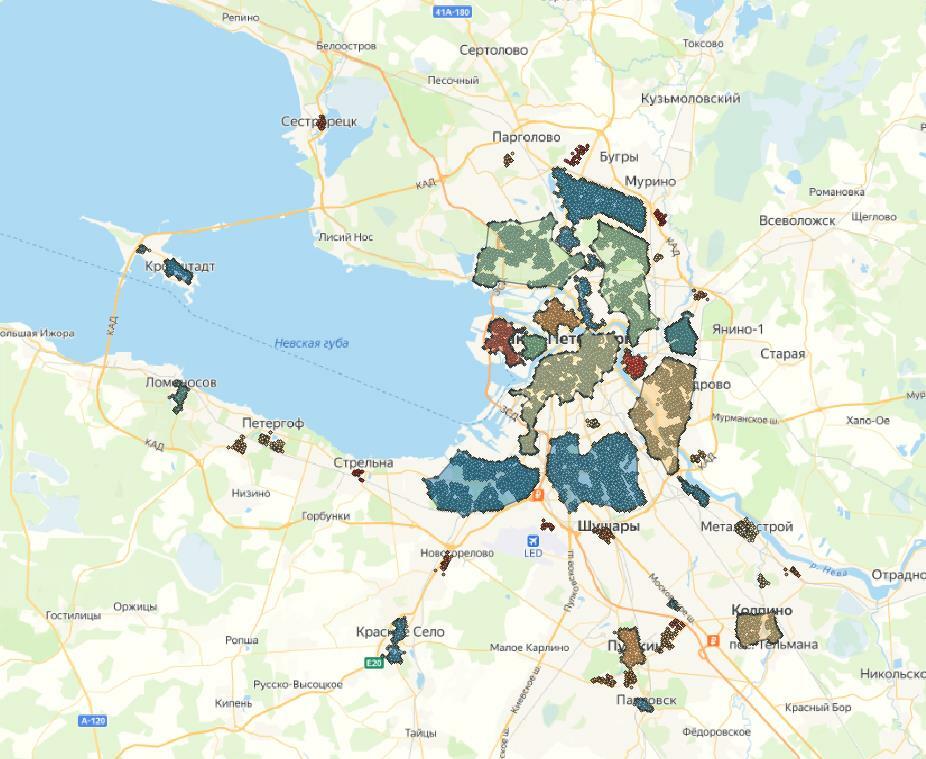
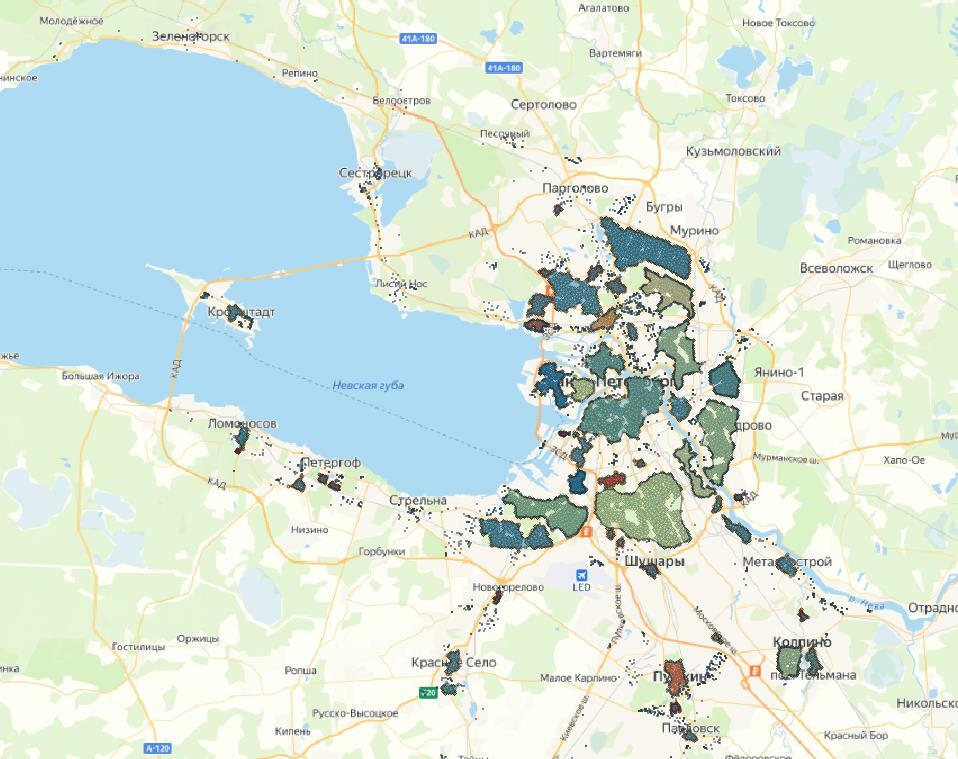
При таких гиперпараметрах четко выделяются плотные области – места с наибольшим количеством точек. Наиболее удачным из всех вариантов оказался вариант с радиусом окрестности 830 метров и минимальным количеством точек 44. На карте с этим результатом также видны точки, которые алгоритм отнес к выбросам, то есть они не попали ни в один кластер.
Основное отличие, которое можно увидеть при кластеризации, используя алгоритм DBSCAN, – это то, что кластеры имеют более четкую форму, так как часть точек попадает в выбросы. Так мы можем более детально интерпретировать территории с большим количеством точек.
Плотностной алгоритм оказался наиболее удачным вариантом для кластеризации пространственных данных.
Другие плотностные алгоритмы
Алгоритм OPTICS сочетает в себе элементы иерархической и плотностной кластеризации. В отличие от DBSCAN, OPTICS не требует заранее заданных параметров радиуса окрестности и минимального числа точек – вместо этого алгоритм строит граф достижимости, который учитывает расстояния между точками и плотность данных. На основании графа определяются плотные области и границы кластеров.
Преимущество OPTICS перед DBSCAN в том, что OPTICS может обнаруживать кластеры различной плотности и формы. А минусом является то, что требуется большое количество вычислений.
HDBSCAN – это алгоритм кластеризации на основе плотности, который строит иерархическую структуру кластеров. HDBSCAN является расширением DBSCAN. Преимуществом алгоритма является то, что на вход ему необходимо задать всего один гиперпараметр – минимальное количество точек, которое должно присутствовать в кластере. Недостаток HDBSCAN – вычислительная сложность алгоритма, особенно при работе с большими объемами данных. По сравнению с DBSCAN или OPTICS для него требуется большее количество вычислений.
Материал подготовила Анна Пикулева
А еще у нас есть рассылка - подпишитесь, чтобы получать по почте лучшие материалы блога, новости мира геотехнологий и полезные ссылки от нашей команды. Письма приходят раз в две недели 💬
