Время прочтения: 8 минут
В прошлом посте этой серии мы уже поговорили в общих словах о кластеризации геоданных и обсудили ее основные принципы. Сейчас сделаем следующий шаг — разберем, какие есть основные алгоритмы кластеризации и сравним их между собой.
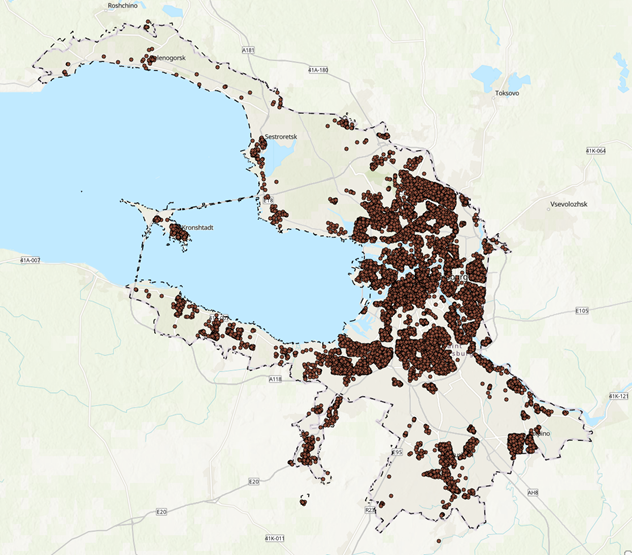
Для иллюстрации каждого алгоритма рассмотрим пример кластеризации пациентов, выделенных по одной болезни. Наша цель – определить, какой метод лучше подходит, чтобы кластеризовать точки и выделить места скопления заболевших.
Что есть в этой статье:
- Пара слов о кластеризации
- Разделительные алгоритмы и их типы
- Алгоритм кластеризации k-means
- Работа с k-means с примерами кода на Python
- Иерархические алгоритмы и их типы
- Агломеративная кластеризация с примерами кода на Python
Пара слов о кластеризации
Кластеризация — это задача группировки данных таким образом, чтобы данные в одной группе (называемой кластером) были более похожи друг на друга, чем данные из других кластеров.
Алгоритмы кластеризации и заданные входные параметры отвечают за то, как именно данные будут разбиты на кластеры, а значит и за правильность кластеризации.
Три основных типа алгоритмов кластеризации:
- разделительные – основаны на поэтапном улучшении разбиения исходного набора данных;
- иерархические – создают иерархию вложенных разбиений;
- алгоритмы на основе плотности – разбивают объекты на кластеры на основе оценки плотности распределения.
Поговорим подробнее о разделительных и иерархических алгоритмах.
Разделительные алгоритмы и их типы
Разделительные алгоритмы (partition clustering) делят объекты данных на непересекающиеся группы. Ни один объект не может находится в более чем одном кластере, и в каждом кластере должен быть хотя бы один объект.
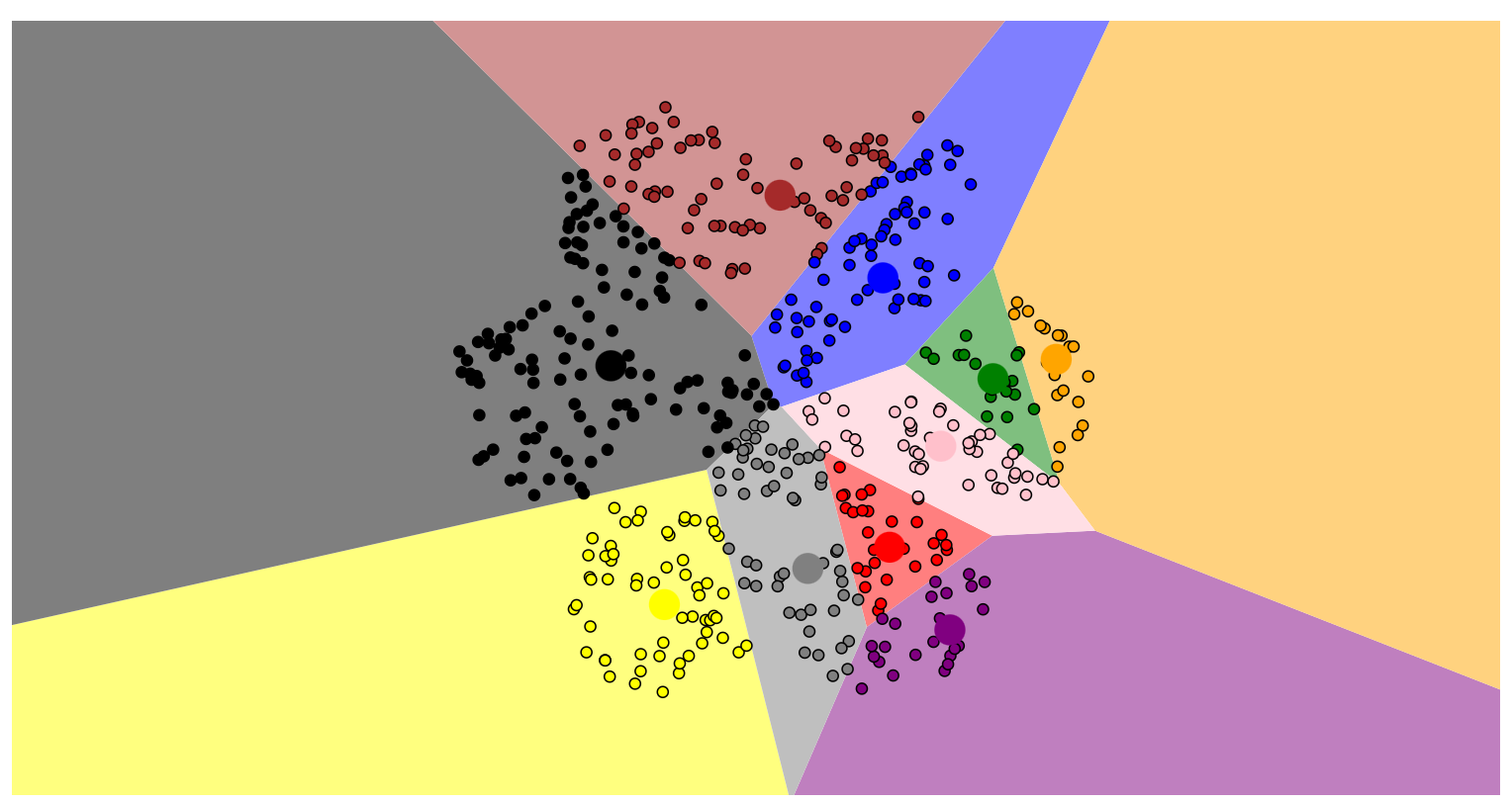
Разделительные алгоритмы чаще всего используются при работе с большими наборами данных, так как они основаны на несложных вычислениях.
Примеры разделительных алгоритмов:
- K-means (ниже рассмотрим, как он работает)
- CLARANS (кластеризация больших приложений на основе рандомизированного поиска)
Где используются разделительные алгоритмы:
В рекомендательных системах, для кластеризации пользователей по группам интересов.
Алгоритм кластеризации k-means
K-means (или метод k-средних) – один из наиболее популярных методов кластеризации. Он не сильно подходит для пространственных данных, но является простым и важным для понимания.
Например, если данных очень много, использовать другие алгоритмы будет затруднительно, и даже в случае геоданных удобнее применить k-means.
Основная идея метода — итеративное повторение двух шагов:
- распределение объектов выборки по кластерам;
- пересчет центров кластеров.
Шаги работы алгоритма кластеризации K-means
- В начале работы алгоритма выбираются K случайных центров.
- Каждый объект выборки относят к тому кластеру, к центру которого объект оказался ближе.
- Далее центры кластеров подсчитывают как среднее арифметическое векторов признаков всех вошедших в этот кластер объектов (то есть центр масс кластера). Центры кластеров обновляются.
- Объекты заново перераспределяются по кластерам, а затем можно снова уточнить положение центров.
- Процесс продолжается до тех пор, пока центры кластеров не перестанут меняться.

Преимущества алгоритма K-means
- Алгоритм k-средних хорошо справляется с задачей кластеризации в случае, когда кластеры линейно разделимы и представляют собой отдельные скопления точек.
- Быстрая работа алгоритма.
Недостатки алгоритма K-means
- Не гарантируется достижение глобального минимума суммарного квадратичного отклонения V, а только одного из локальных минимумов.
- Результат зависит от выбора исходных центров кластеров, их оптимальный выбор неизвестен.
- Число кластеров надо знать заранее.
Реализация k-means на примере
Все расчеты проводились в Python с библиотекой sk-learn.
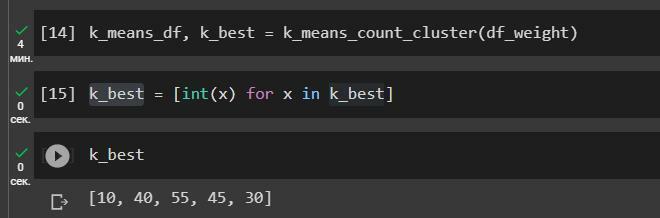
На вход алгоритму k-means необходимо задать гиперпараметр – количество кластеров, на которое будут разбиты данные. Первым шагом необходимо определить это значение. Для этого итерационно запускаем алгоритм с количеством кластеров от 1 до 100 и при этом оптимизируем четыре основные метрики кластеризации (о метриках качества поговорим в следующих статьях).

На выходе функции получаем датасет с количеством кластеров и значением метрик кластеризации. Берем пять первых значений.
В результате мы получили, что оптимальным количеством будет 10, 40, 55, 45, 30 кластеров.
Далее переходим к запуску алгоритма.
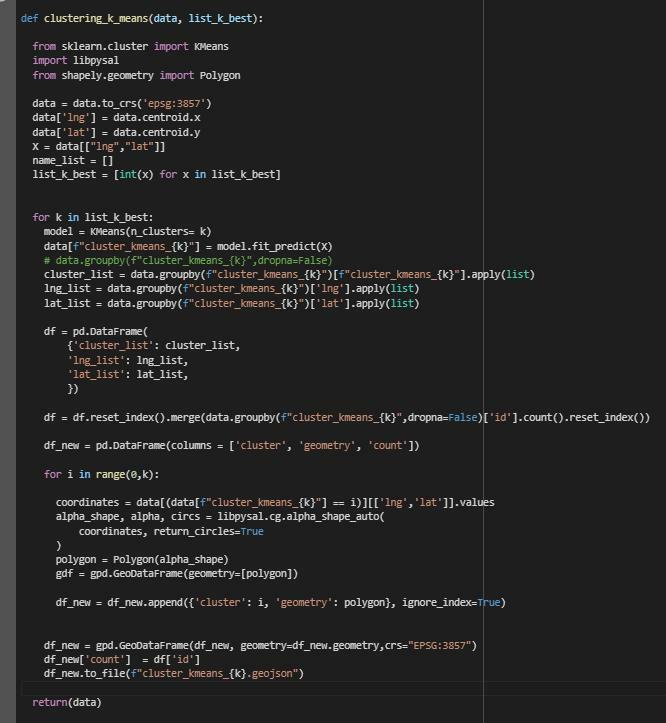
Для каждого алгоритма кластеризации были написаны функции:
- Функция, которая принимает на вход данные и список с наилучшим количеством кластеров.
- В ходе работы функции ко всем точкам из датасета добавляется поле с номером кластера, к которому они были отнесены.
- Для более понятной визуализации точки с одинаковым значением кластера объединяются в альфа-форму – полигон, который объединяет самые выпуклые точки. Подсчитывается количество точек в каждой альфе-форме. Файлы с альфа-формами сохраняются в формате geojson.
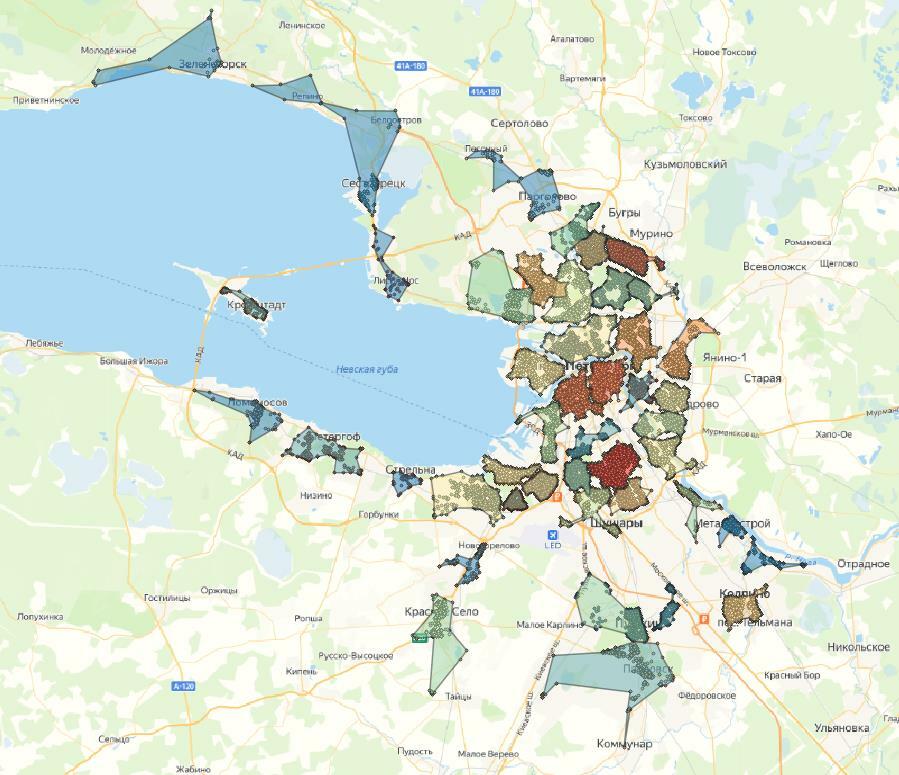
Давайте посмотрим, какие кластеры у нас получились. На выходе получаем столько видов кластеризации, сколько различных гиперапараметров было задано – в нашем случае получили 5 вариаций.
На картах цветовая шкала кластеров зависит от количества точек. Поверх отображены сами точки.
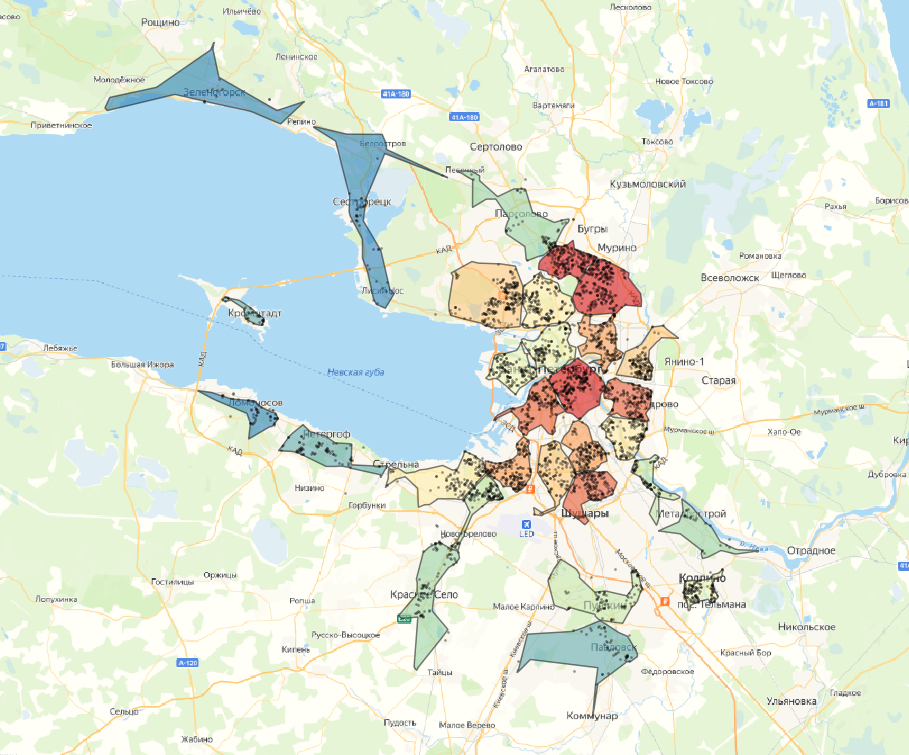
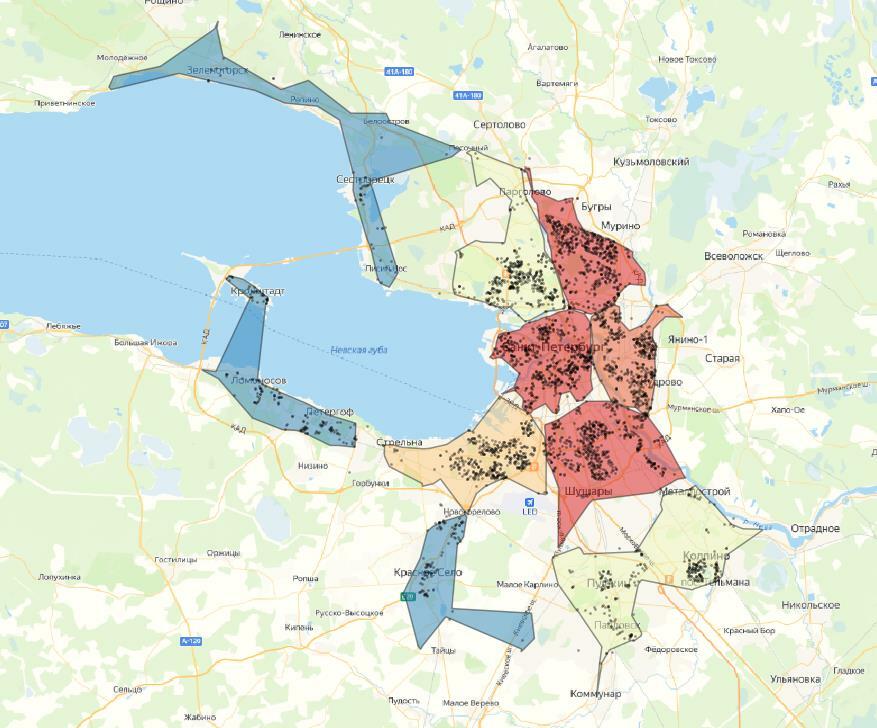
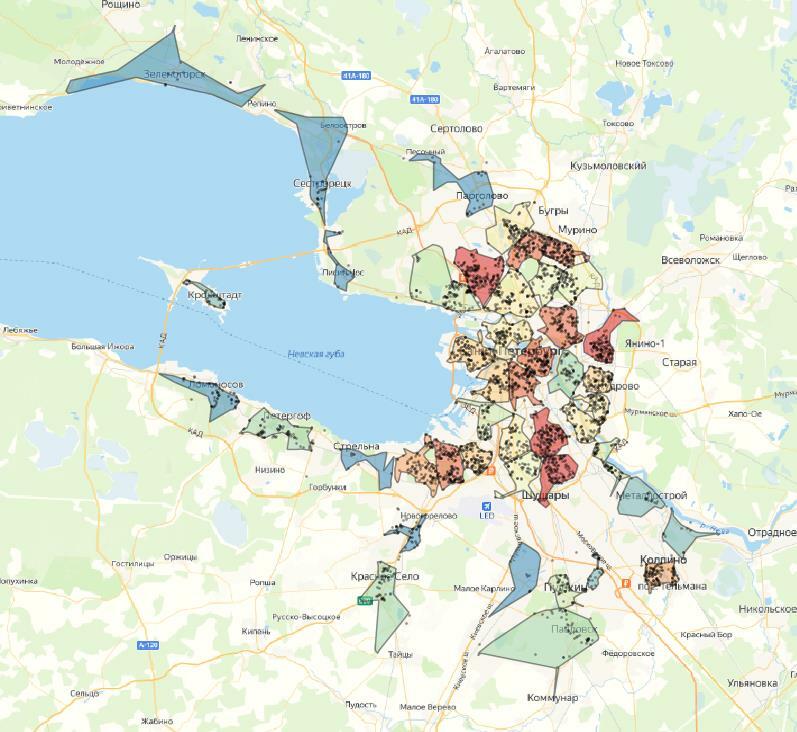

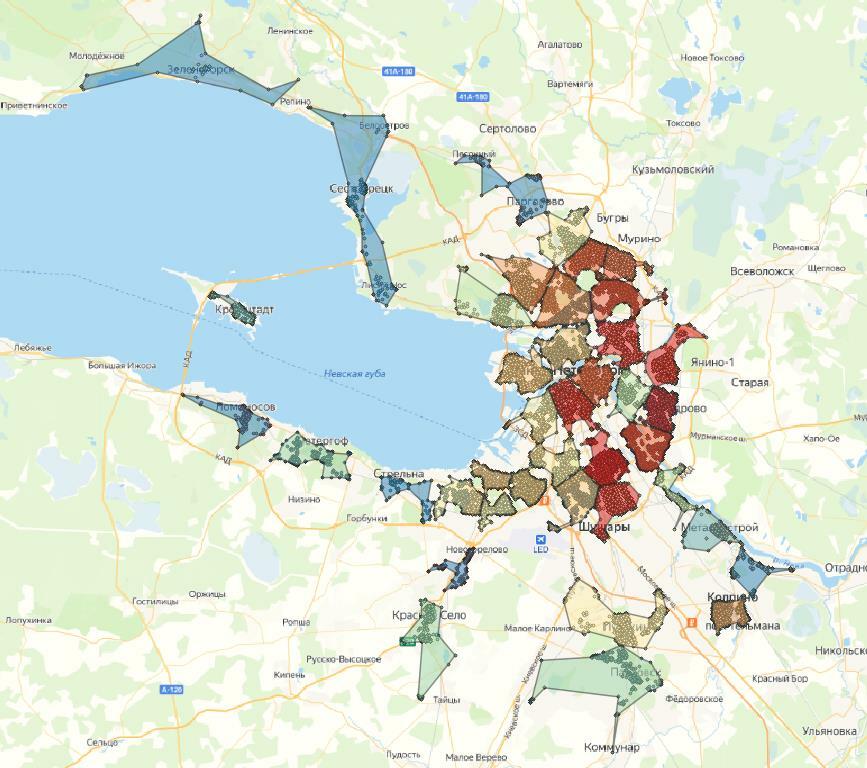
Результат – с k-means точки довольно четко группируются на кластеры. Заметно, что при 10 кластерах в одном кластере может быть до двух-трех скоплений точек, что в нашем случае не является правильным. При 20 кластерах таких случаев меньше, и кластеры довольно четко разделены.
Если мы берем еще меньшее деление, видно, что некоторые скопления делятся на два и более частей, что неправильно для нашей задачи. Поэтому лучший вариант, основанный на визуальной составляющей – это 20 кластеров.
На всех примерах заметно, что есть значительная часть точек-выбросов, которые находятся далеко от центра кластера, из-за чего альфа-формы получаются неправильной формы. Этого можно избежать, используя плотностные алгоритмы, которые умеют определять выбросы, или заранее отфильтровать датасет и выявить выбросы.
Иерархические алгоритмы кластеризации
Алгоритмы иерархической кластеризации используются для обнаружения основных закономерностей в наборе данных для проведения статистических исследований.
Типы иерархических алгоритмов кластеризации:
- Агломеративные (от меньшего к большему) – одиночные объекты постепенно объединяются в кластер.
- Разделительная кластеризация (от большего к меньшему): все данные собираются в один кластер и далее происходит деление на два, четыре и так далее кластеров.
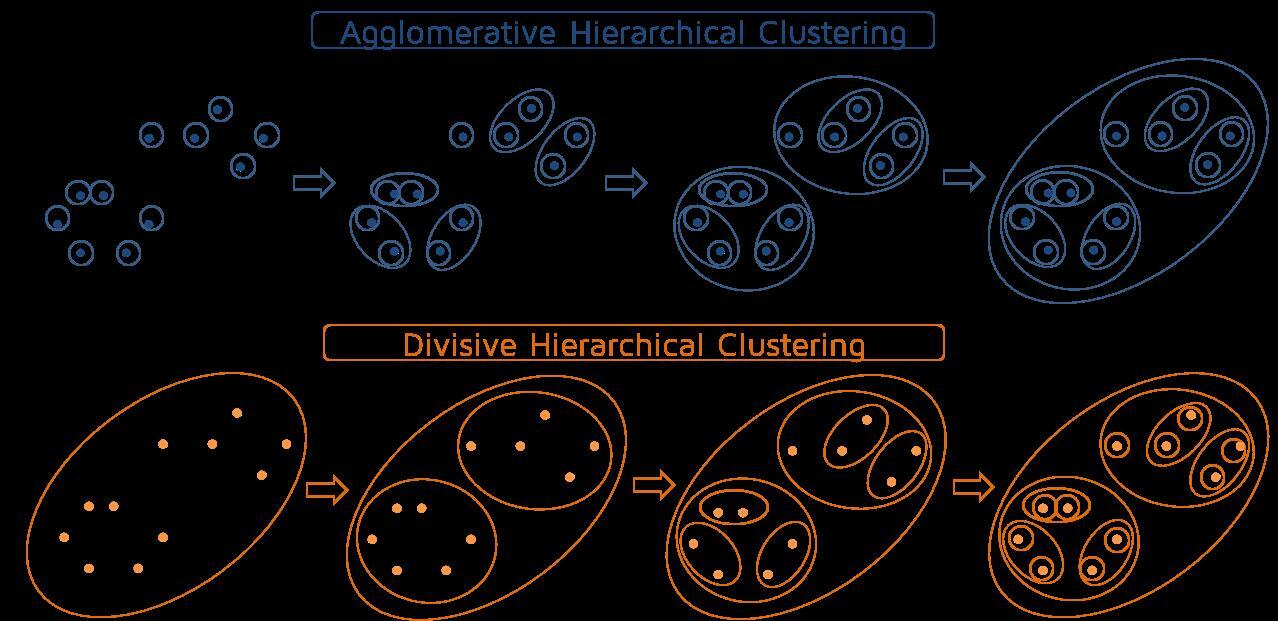
Источник: https://quantdare.com/hierarchical-clustering/
Принцип работы алгоритма
Для работы этих алгоритмов определяется матрица близости, которая содержит попарные расстояния между всеми объектами. На основании нее происходит объединение или разделение объектов.
Когда в одном кластере более одного объекта, берется среднее расстояние.
После каждой итерации заново рассчитывается матрица близости.
Условия окончания работы алгоритма
Для завершения работы алгоритма можно выбрать одно из условий:
- Получено нужное количество кластеров.
- Достигнуто определенное условие, связанное с расстоянием между кластерами – например, если оно сильно изменилось с прошлой итерации.
- Анализ по дендрограмме. На практике обычно кластеризацию проводят вплоть до одного кластера, включающего в себя всю выборку, а затем анализируют получившуюся иерархическую структуру с помощью дендрограммы.
Пример агломеративной кластеризации
Проведем агломеративную кластеризацию, используя в качестве точки остановки заданное количество кластеров.
Для агломеративной кластеризации тоже сначала рассчитаем оптимальное количество кластеров исходя из метрик кластеризации, как и с методом k-means. Для этого напишем функцию, которая разбивает данные от одного до ста кластеров и сравнивает полученные кластеры по трем метрикам.
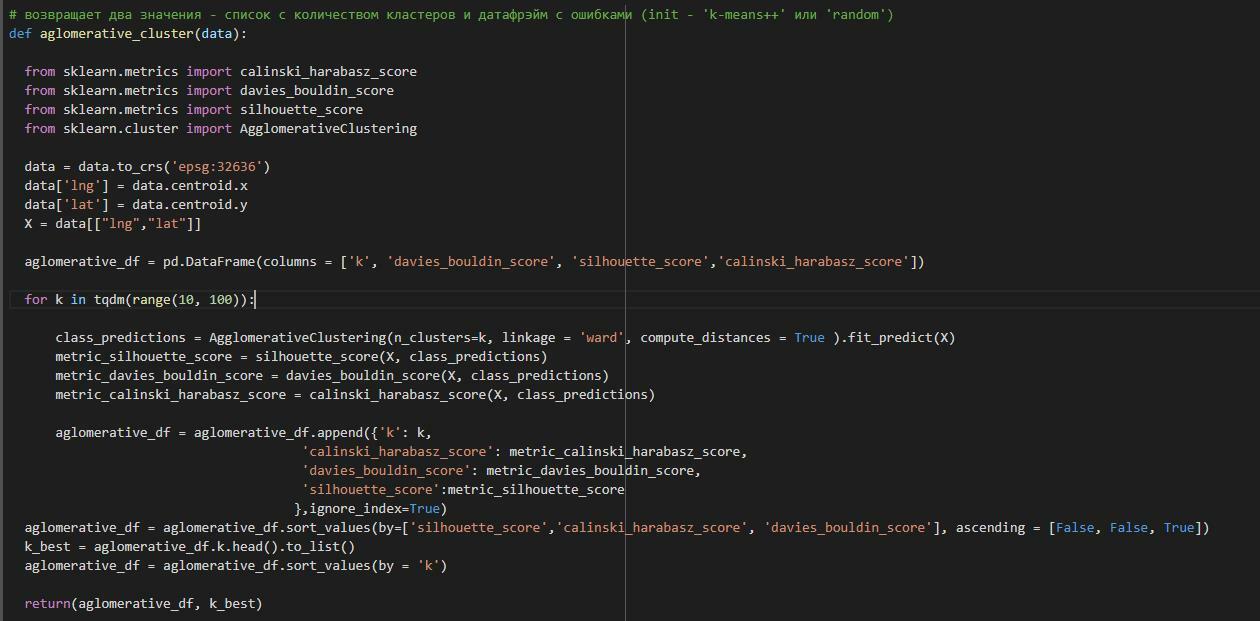
Оптимальное количество кластеров: 40, 25, 45, 20 и 35.
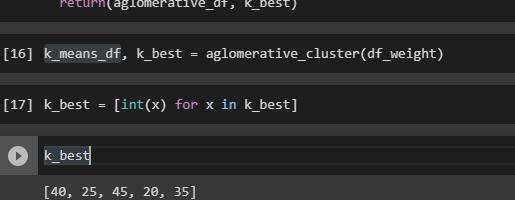
Следующий шаг – написать функцию, которая производит кластеризацию с нужными гиперпараметрами.

Как и в k-means, на вход этой функции подается датасет с точками. Далее производится кластеризация. В итоге мы получаем альфа-формы и датасет с точками, которые имеет значение кластеров.
Посмотрим на кластеры, которые у нас получились.
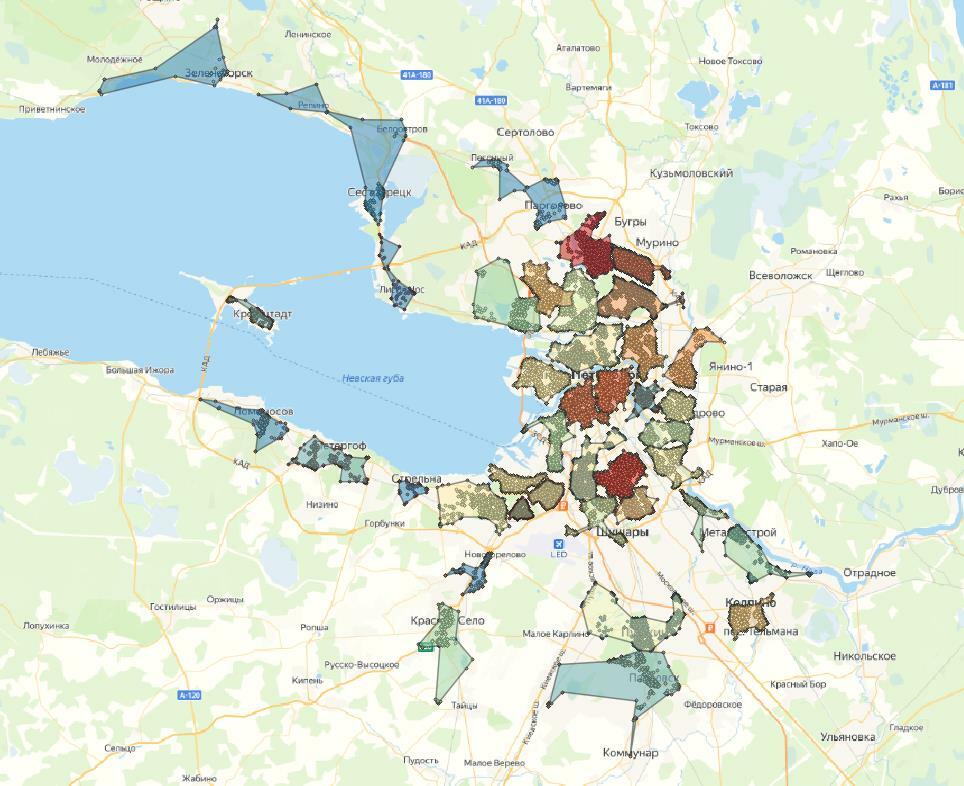
В случае алгомеративной кластеризации наиболее оптимальным числом кластеров мне показалось 30. В этом случае четче всего выделяются скопления точек. Однако, как и в алгоритме k-means, мы видим, что кластеры объединяют даже те точки, которые можно было считать выбросами.
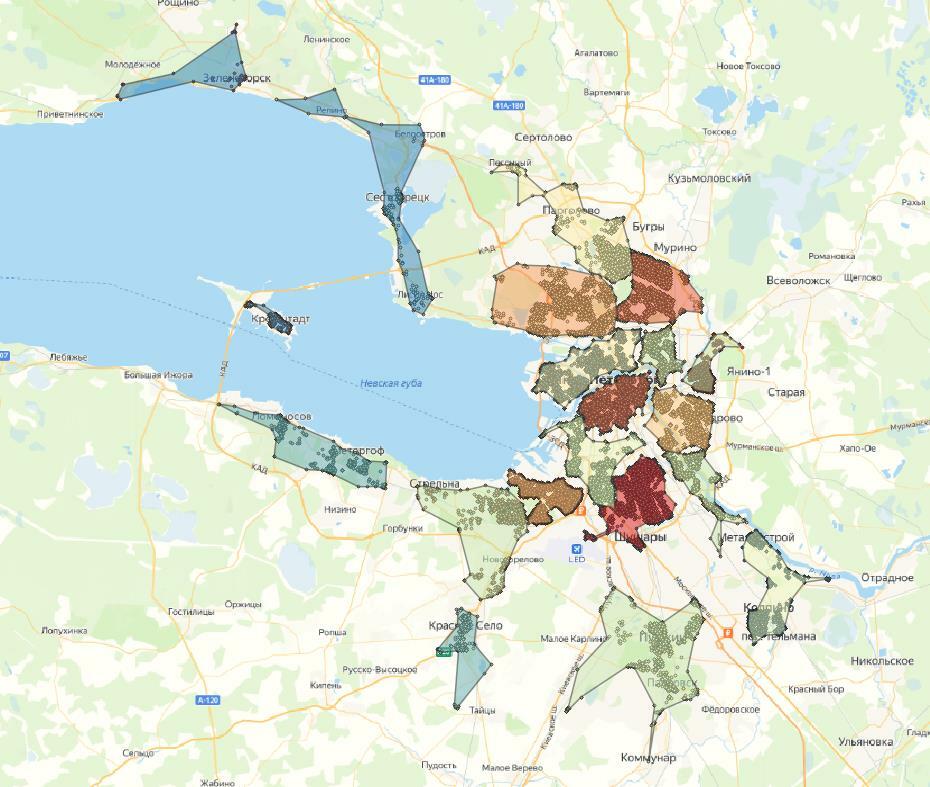

Можно сделать вывод, что методы разбиения и иерархическая кластеризация помогают находить кластеры более-менее ровной формы, а с кластерами нетипичной формы они справляются хуже.
K-means и иерархическая кластеризация отлично справляются с задачей кластеризации компактных и хорошо разделенных кластеров.
В следующем тексте этой серии рассмотрим плотностные алгоритмы, наиболее подходящие для кластеризации пространственных данных. И если вы хотите узнать больше, мы всегда готовы научить вас работе с геоданными в Python и QGIS.
Материал подготовила Анна Пикулева
А еще у нас есть рассылка с лучшими статьями и новостями мира геотехнологий. Собираем все лучшее и отправляем в письме раз в две недели ⭐
