Время прочтения: 4 минуты
Введение
В недавней статье нашего блога Юлия Федорова затронула тему оптимизацию вычислительных процессов на примере задачи коммивояжера. Когда данные начинают исчисляться десятками тысяч объектов, различные пространственные вычисления могут занимать огромное количество времени даже на таких мощных персональных компьютерах, которые могут открывать сразу 3 или даже 4 вкладки в гугл хроме. В этой статье вы узнаете, как можно очень быстро и легко ускорить любые ваши пространственные вычисления вне зависимости от мощности железа с помощью пространственного индекса (spatial index).
Индексирование
Индексирование изначально было придумано для работы с обычными табличными данными и по своей сути больше похоже на то, как мы работаем с книгой и содержанием. Например, мы открыли книгу по географии и хотим прочитать про Южную Америку. Мы можем просто листать каждую страницу книги, пока не долистаем до нужно раздела, что займет много времени, либо открыть оглавление, увидеть, на какой странице рассказывается про Южную Америку, и сразу перейти на ее. В этом и состоит примерная суть индексирования: это создание какого-то отдельного раздела, по которому мы можем понять, где какие данные.
Если посмотреть под капот процесса, то там все будет несколько сложнее, но для понимания достаточно этой аналогии.
Если посмотреть под капот процесса, то там все будет несколько сложнее, но для понимания достаточно этой аналогии.
Пространственный индекс
Пространственный индекс географических базах данных (в том числе в наших слоях) — это механизм, который позволяет оптимизировать доступ к данным с пространственной привязкой. Этот механизм есть во многих геоинформационных системах (например, в QGIS и ArcGIS) и системах управления базами данных, которые могут работать с пространственными данными, например PostGIS от PostgreSQL.
Стандартные индексы непространственных баз данных создают иерархическое дерево на основе значений индексируемого столбца, похожее на содержание с подразделами. Пространственные индексы немного отличаются: они не могут индексировать сами геометрические объекты, а вместо этого индексируют ограничивающие рамки объектов. В одну рамку входит сразу множество объектов. Поэтому если мы захотим узнать, пересекается ли определенный регион с определенными объектами, то алгоритм сначала проверит, с какими пространственными индексами пересекается регион. Это позволит очень быстро отбросить сразу множество объектов и не тратить время на их перебор. То есть программе не надо будет спрашивать у каждой точки: “Пересекаешься ли ты с регионом?”
Чтобы было понятнее, попробуем разобраться с помощью представленной ниже картинки.
Стандартные индексы непространственных баз данных создают иерархическое дерево на основе значений индексируемого столбца, похожее на содержание с подразделами. Пространственные индексы немного отличаются: они не могут индексировать сами геометрические объекты, а вместо этого индексируют ограничивающие рамки объектов. В одну рамку входит сразу множество объектов. Поэтому если мы захотим узнать, пересекается ли определенный регион с определенными объектами, то алгоритм сначала проверит, с какими пространственными индексами пересекается регион. Это позволит очень быстро отбросить сразу множество объектов и не тратить время на их перебор. То есть программе не надо будет спрашивать у каждой точки: “Пересекаешься ли ты с регионом?”
Чтобы было понятнее, попробуем разобраться с помощью представленной ниже картинки.

Наша задача простая — узнать, с какой линией пересекается звезда. Если пространственного индекса нет, то программа будет спрашивать у каждой линии: “Ты пересекаешься со звездой?”
Если же у слоя линий есть пространственный индекс, то программа спросит сначала, с какими пространственными индексами пересекается звезда, а затем уже будет спрашивать у каждого объекта внутри. Этот механизм очень ускоряет процесс, когда у нас не звезда и три линии, а звезда и тридцать тысяч линий.
Существуют разные алгоритмы создания пространственных индексов, самый частый — алгоритм R-tree, который используется в большинстве геоинформационных систем по умолчанию, например, в QGIS или ArcGIS. Также он является основным для PostGIS и Oracle Spatial.
Алгоритм R-tree как раз и делит территорию на прямоугольники, как указано выше, причем он может создавать иерархические структуры, когда внутри одного условного прямоугольника-пространственного индекса создаются прямоугольники поменьше.
Если же у слоя линий есть пространственный индекс, то программа спросит сначала, с какими пространственными индексами пересекается звезда, а затем уже будет спрашивать у каждого объекта внутри. Этот механизм очень ускоряет процесс, когда у нас не звезда и три линии, а звезда и тридцать тысяч линий.
Существуют разные алгоритмы создания пространственных индексов, самый частый — алгоритм R-tree, который используется в большинстве геоинформационных систем по умолчанию, например, в QGIS или ArcGIS. Также он является основным для PostGIS и Oracle Spatial.
Алгоритм R-tree как раз и делит территорию на прямоугольники, как указано выше, причем он может создавать иерархические структуры, когда внутри одного условного прямоугольника-пространственного индекса создаются прямоугольники поменьше.
Насколько эффективен пространственный индекс
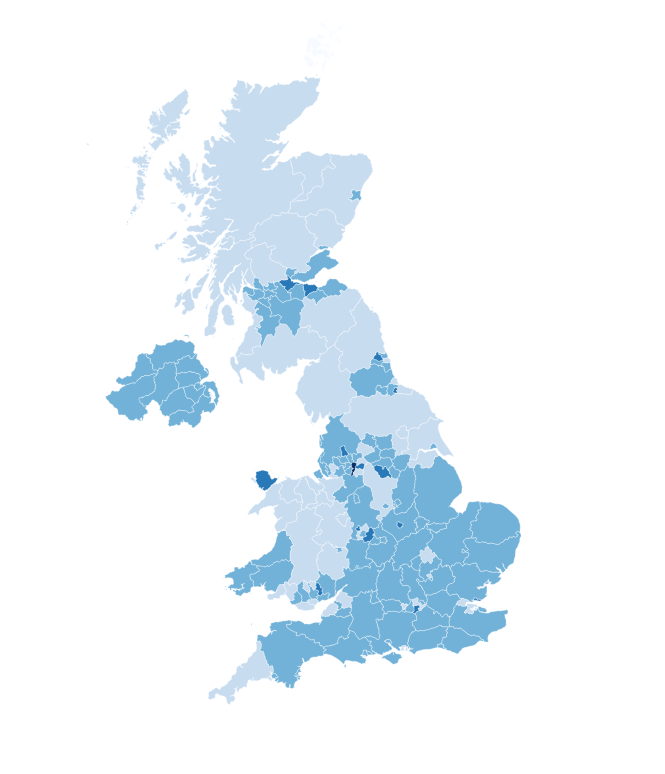
Сейчас я продемонстрирую, как пространственный индекс ускоряет процессы. Для этого подготовил 2 пары слоев, в одной есть пространственные индексы, в другой нет. Один слой — административное деление Великобритании, площадной слой из 183 объектов, а другой слой — топонимы Великобритании (источник), точечный слой, в котором 87416 объектов.

Для примера я посчитал, сколько символов в каждом топониме, и теперь хочу найти графство Великобритании, в котором в среднем самые длинные названия топонимов (мера среднего — медиана).
При использовании слоев с пространственным индексом расчеты заняли у меня 6,05 секунды. Без использования пространственного индекса расчеты заняли уже 13,30 секунды. Двукратная экономия времени.
При использовании слоев с пространственным индексом расчеты заняли у меня 6,05 секунды. Без использования пространственного индекса расчеты заняли уже 13,30 секунды. Двукратная экономия времени.

Чем больше у вас данных, тем сильнее пространственный индекс ускоряет вычисления, что может не просто сэкономить вам секунды или часы, а даже стать единственной возможностью использовать функции программы полностью. При работе с ГИС встречаются такие ситуации, в которых программа при слишком больших вычислениях просто не может завершить их до конца и зависает. Пространственный индекс же за счет оптимизации дает возможность сделать операцию до конца (но тоже не всегда).
Если вы хотите узнать больше про то, какими бывают пространственные индексы и как их создавать, то можете прогуляться по ссылкам ниже. А также поделитесь в комментариях в наших соцсетях, какой у вас есть опыт использования пространственных индексов?
Если вы хотите узнать больше про то, какими бывают пространственные индексы и как их создавать, то можете прогуляться по ссылкам ниже. А также поделитесь в комментариях в наших соцсетях, какой у вас есть опыт использования пространственных индексов?
Что еще почитать:
- Про разные виды пространственных индексов
- Как создавать пространственный индекс для шейп-файла в QGIS (чтобы создать пространственный индекс для gpkg, просто зайдите в свойства слоя, затем в раздел "Текст", в нем ищите подраздел геометрия и заветную кнопку “Создать пространственный индекс”)
- Про пространственные индексы в ArcGIS